ついに機械学習に入ります。今回はサポートベクターマシン(SVN)。この本マジでわかりやすい。

尾崎 隆
技術評論社
売り上げランキング: 141,877
技術評論社
売り上げランキング: 141,877
SVNをやる前に~そもそも機械学習って何か
本から引用します。
- 機械学習には、教師あり学習と教師なし学習がある
- 教師あり学習(Supervised Learning):人が「このようなクラス分類結果にすべき」という基準になる学習データを与えたうえで、そのような結果になるように分類パラメータを調整するアルゴリズムに基づく機会学習
- クラス1とクラス2はそれぞれ異なる分布を持つ母集団から得られたものであるという過程を置くのが通例
- 未知データがクラス1、クラス2の母集団に同じように分布しているとしたら、このクラス分類モデルは「未知データに対しても最適な」モデルといえる
- 学習データのクラス分類と未知データのクラス分類は同じである

- クラス分類のモデル性能を調べるために交差検証法(Cross Validation)を使う
- 学習データからランダムに一部を取り出し、これを除いたデータで暮らす分類モデルを推定⇒おの一部のデータに対してクラス分類モデルをあてはめてみて、正答率が正しければOK
- これによってオーバーフィッティング(過学習)を防げる
- 教師あり学習の分類:学習パラメータの調整によって、3種類に分かれる
- 識別モデル
- 単純パーセプトロン
- ニューラルネットワーク
- サポートベクターマシン(SVN)
- Passive-Aggressive法
- 生成モデル
- ナイーブベイズ分類木
- ベイジリアンモデリング各種
- 樹木モデル
- 決定木(前回やった)
- 回帰木(前回やった)
識別モデルとは何か
- 何かしらの境界線を仮に定め、学習データに従って、その識別境界がベストのクラス分類結果を返すようにパラメーターを調整していく方法


教師なし学習とは何か
- 学習データのサンプル間の距離や類似度、統計的性質に基づいて、クラス分類を自動的に作り出すという方法
- クラスタリングは教師なし学習の典型
- データマイニングでは、教師なし学習を指していることが多い(まだ見知らぬクラス分類を探すから)
- ベイジリアンモデリングの多くはその意味合いのもとで使われることが多い
教師あり学習のサポートベクターマシン(SVN)のメインロジック:マージン最大化とカーネルトリック
- マージン最大化:二つの分類クラス間の距離をできるだけ広くとる
- 以下の図のように、二つの分類クラスの幅を最大化させる

- ただし、これだけだと、線形分離不可能(linearly inseparable)な(まっすぐ線、面で切り分けられない)
- カーネルトリック:データを数理的に変換することで強制的に線形分離できる語りにデータの見掛けを変えてしまうロジック。マージン最大化の欠点を補える
- 下のような図を見ると、単純に線で区切ることができない
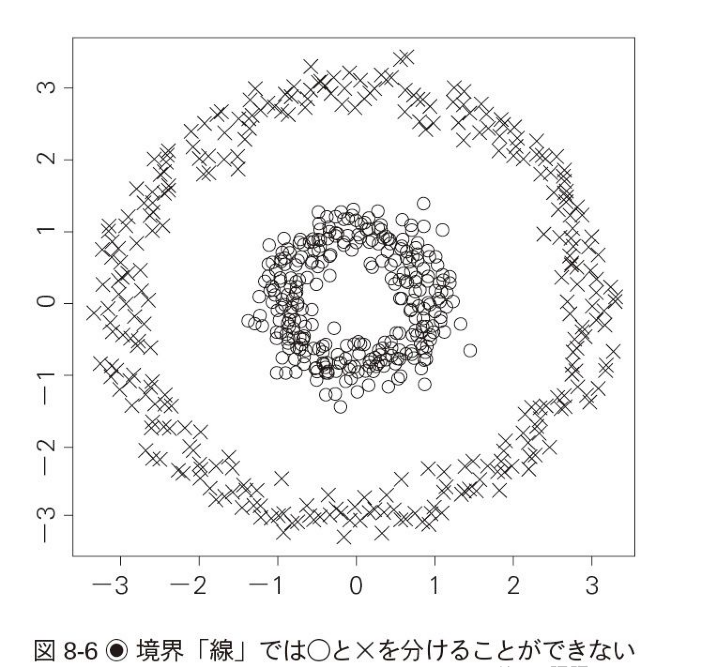
- しかし、ガウンシアンカーネルと呼ばれるカーネル関数を用いて3次元空間に変換し、線形で区別することができる


- マージン最大化と、カーネルトリックによって、SVNは汎化能力の高い機械学習分類器として知られる。
SVNを使って、新規ユーザーの属性データから、一カ月後のアクティブユーザー数を予測する
- あるソーシャルゲームにおけるある日付の新規ユーザーの属性データから、一カ月後もゲームをプレーしてくれるユーザー数がどれくらいになるかを予測する
- 手元には、10000人分の過去ユーザーの属性データがあることを想定
- 年齢(age)
- 性別(sex)
- 新規登録当日にチュートリアルを突破したか(act1)
- ガチャを引いたか(act2)
- 流入経路(influx)
- 一か月後もアクティブか(label)

- 新規登録ユーザー500人の属性データから、未知データをあてはめて、1カ月後アクティブかどうか予測する
- 学習データと、テストデータをインポートする(著書のページから)
- 学習データ:d.train
- テストデータ:d.test
- とりあえず、データの中身を見る
- 訓練データにのみ、labelという、アクティブユーザーを識別できるようになっている。
- テストデータには、labelは存在しない
> install.packages("e1071") #SVN用のパッケージ > require("e1071") > head(d.train) #訓練用のデータを見る age sex act1 act2 influx label 1 28 M Yes Yes C No 2 34 M Yes Yes A Yes 3 33 M No Yes A No 4 40 M No No A Yes 5 30 F Yes Yes A No 6 31 M No Yes C No > head(d.test) #テスト用のデータを見る。labelが存在しない。 age sex act1 act2 influx 1 31 F No Yes B 2 32 F No Yes C 3 33 F Yes No C 4 34 M No Yes A 5 36 F No Yes C 6 27 M Yes No B
- サポートベクターマシンで実装する。
> d.svm <- svm(label~.,d.train) #目的変数と、説明変数を代入 > print(d.svm) Call: svm(formula = label ~ ., data = d.train) Parameters: SVM-Type: C-classification SVM-Kernel: radial cost: 1 gamma: 0.1428571 Number of Support Vectors: 1502 > d.test.svm.pred <- predict(d.svm,newdata=d.test) > summary(d.test.svm.pred) No Yes 471 29
- 500人中、1カ月後にアクティブユーザーになるのは29人、残りの471人は離脱するという予測結果になる。
- 内部パラメータをチューニングすることによって、クラス分類の性能を向上させることができる(tune.svm関数)
- ただし、svn関数はある程度パラメーターをチューニングしてくれているらしい
考えたこと
- すっごくざっくりSVNとまとめると、
- 教師データで、Yes or Noの識別を行い、Yesの母集団のグループと、Noの識別のグループを分ける
- なんかよくわからないけど、そのYesとNoのグループをきっぱりと分けてくれる分割線を引いてくれる
- その結果、テストデータを教師データの母集団分布にぶち込んで、Yes or Noのところに分布に当てはめる
- みたいな感じなのかぁと
本に書いていないけど、気になって調べたこと
- もとからデータが与えてられないときに、どういう風に使えばいいかわからない
尾崎 隆
技術評論社
売り上げランキング: 141,877
技術評論社
売り上げランキング: 141,877


