AIで似ているAV女優を紹介しているスケベAI「スケベ博士」を作りました。①アプリ紹介編 の続きです。実際にどう実装したかという話です。
まだ友達追加していない人はここからチェケラ
https://line.me/R/ti/p/6XAcvOifDl
2018-03-22
2018-03-03
Python 機械学習のための画像収集①:アダルトサイトからAV女優6000名の名簿データをスクレイピングし、スプレッドシートを公開しました
#やりたいこと
- Microsoft AzureのFace APIを使って、Lineから送られてきた画像から、似ているAV女優を取得する
#やりたいこと— Dai Kawai@RubyPython (@never_be_a_pm) March 3, 2018
そっくりなび、の精度が低すぎ。
あとAV女優の名前がクリックしないとわからないのもよくない。
俺が知りたいのは友達に似ているAV女優の名前であって、アフィリエイトコード入った商品のURLではない。https://t.co/HPleEt68Vw pic.twitter.com/aLEeQ9uAxl
2018-01-13
Ubutnu PythonでChromedriverがインストールできないときの対処法
Ubutnu PythonでChromedriverがインストールできないときの対処法のメモ。
結論から言うと、最新バージョンのChromedriver入れれば治る。
selenium.common.exceptions.SessionNotCreatedException: Message: session not created exception chromedriver
とか
selenium.common.exceptions.WebDriverException: Message: unknown error: missing or invalid 'entry.level'
とか、だいたいChromedriverのバージョンの問題らしいですぜ。
普通にChromedriver Ubuntuみたいに調べると、過去のQiitaの記事とかが上位に出るので、Chromedriver latestとかで調べるとよさそう。
結論から言うと、最新バージョンのChromedriver入れれば治る。
selenium.common.exceptions.SessionNotCreatedException: Message: session not created exception chromedriver
とか
selenium.common.exceptions.WebDriverException: Message: unknown error: missing or invalid 'entry.level'
とか、だいたいChromedriverのバージョンの問題らしいですぜ。
#案件— Dai Kawai@RubyPython (@never_be_a_pm) January 13, 2018
ChromeDriverが古いのでアプデが必要。
selenium.common.exceptions.SessionNotCreatedException: Message: session not created exception chromedriverhttps://t.co/wFp9LYoPpc
#案件— Dai Kawai@RubyPython (@never_be_a_pm) January 13, 2018
同様に古いらしい
最新版にしろってことか。
selenium.common.exceptions.WebDriverException: Message: unknown error: missing or invalid 'entry.level'https://t.co/gcnkYc65Vq
— Dai Kawai@RubyPython (@never_be_a_pm) January 13, 2018
普通にChromedriver Ubuntuみたいに調べると、過去のQiitaの記事とかが上位に出るので、Chromedriver latestとかで調べるとよさそう。
2017-12-23
【Python x Selenium】Instagramでタグ検索し、取得した写真にすべていいねできる自動化ツールを作成しました

結論から言うと、Instagramで自動でいいねできるツールを作りました。
実装内容としては
- ログインページで認証
- 指定したタグで検索
- 写真にいいね
- 次へボタンが存在しなくなるまで永遠に指定したタグのいいねをし続ける
って感じです。

そもそもInstagramに何も興味なかった
普段全然興味なくて使っていないInstagram。
最後に使ったのは、浴衣姿の女子大生が見れると聞いてインストールしたとき以来でした。しかし実際に使ってみて、インストールした初月は水着美女や浴衣姿をたくさんと、女子大生のクッソどうでもいいスターバックスの投稿やらなんやらで、こんなくそアプリ穴を吹く紙にもならんなと思ったのでした。
Instagramに興味をもった理由
しかし、ここ最近再び興味を持ったのは、Instagramの自動ツールが割と需要があるという点でした。例えばLancersとかCloud Worksとか見ていると、ちらほらInstagramの自動化ツールの作成依頼が5-10万円くらいの単価で存在していたりとか。
あとは知り合いで実際にInstagramの自動化ツールを有料で利用している人がいたので、なるほどぉと思って興味を持ちました。
Instagramでマーケティングとは?
Instagramは結構マーケでも注目されているそうで、例えばこの辺の記事とか参考になりそうです
で、どういう風にInstagramをマーケティングで使っているんだろうなんて調べてみましたが、基本的には特定のタグで写真を投稿している人にいいねをすることで、集客を促進しているようですね。
例えば、たまたま#よみうりランドというコメントで検索した際に見つけた画像ですが、こんな感じです。
面白いですよね、よみうりランドに近いところのハッシュタグを利用して、そのように集客につなげるっていう戦法みたいですね。おそらくいいねすると近くにお店があることがわかるので、集客につながるんだと思います。
確かに、こうすると割と地域に応じたマーケとかもできそうで、よさそうですね。
商用化されているInstagramマーケティングツールを見ていると、
- 特定のハッシュタグを選択
- 定期実行プログラムにて、そのハッシュタグに対して投稿している人にたいしていいねを実行
というのが大半なようです。例えば、ハッシュライクというサイトでは、いいねを自動化させることができます。30日3600円で、指定したタグを設定し、定期実行でいいねをしてくれるようです。
— DAI (@never_be_a_pm) December 19, 2017

ということで、この機能を今回は実装しました。
実装方法
この機能を実装するためには、当初二つ方法がありました。一つはInstagramの公式APIを利用してやる方法、もう一つはWebスクレイピングでごり押しする方法です。
前者を最初に試したのですが、どうやら2016年度にAPIの利用制限がかかり、自分の写真しか見れなくなるという、どうしようもないAPI仕様になってしまったようです。(Sandboxモードという、開発者向けお試し用)
これを無制限にするための審査が非常に面倒になりました。実際にAPIを利用したプロダクトを作成し、さらにその動画までつくってInstagramに送らなければいけないみたいです。しかもその審査もかなり厳しいようで、普通に利用するにはかなりハードルが高いようです。
できればこちらを利用したほうがよいのですが、ちょっと難しそうなので安定のSeleniumでごりおし作戦にしてみました。
環境
* Windows 10
* WSL
* Selenium
* Chrome Driver
ソースコード
usernameとpasswordを入れれば、おそらく動くかと。
日本語検索で少し困りましたが、URLのエンコーディング周りだったのが原因でした。
動くのですが、Webelementを複数取得したときに、Webelementの最初だけ取得する方法がわかりませんでした。わかる人がいらっしゃいましたら教えて下さい。
api.py
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.parse
import time
#Webdriver
browser = webdriver.Chrome(executable_path='/mnt/c/workspace/pydev/chromedriver.exe') #ここには任意のWebdriverを入れる
#URL
loginURL = "https://www.instagram.com/" #ログインする際のページ
tagSearchURL = "https://www.instagram.com/explore/tags/{}/?hl=ja" #.format()で{}の中の値を入れられるようになっている
#TagSearch
tagName = "よみうりランド" #タグの名前 #よみうりランド
#selectors
#ここには書くページのSelectorを選ぶ。x-pathもしくはcss selector
loginPath = '//*[@id="react-root"]/section/main/article/div[2]/div[2]/p/a' #xpath @https://www.instagram.com/
usernamePath = '//*[@id="react-root"]/section/main/article/div[2]/div[1]/div/form/div[1]/div/input' #xpath @https://www.instagram.com/
passwordPath = '//*[@id="react-root"]/section/main/article/div[2]/div[1]/div/form/div[2]/div/input' #xpath @https://www.instagram.com/
notNowPath = '//*[@id="react-root"]/div/div[2]/a[2]'
mediaSelector = 'div._e3il2' #表示されているメディアのwebelement @https://www.instagram.com/explore/tags/%E3%82%88%E3%81%BF%E3%81%86%E3%82%8A%E3%83%A9%E3%83%B3%E3%83%89/?hl=ja
likeXpath = '/html/body/div[3]/div/div[2]/div/article/div[2]/section[1]/a[1]'
nextPagerSelector = 'a.coreSpriteRightPaginationArrow' #次へボタン
#USER INFO
username = ""
password = ""
#list
mediaList = []
#counter
likedCounter = 0
if __name__ == '__main__':
#Login
browser.get(loginURL)
time.sleep(3)
browser.find_element_by_xpath(loginPath).click()
time.sleep(3)
usernameField = browser.find_element_by_xpath(usernamePath)
usernameField.send_keys(username)
passwordField = browser.find_element_by_xpath(passwordPath)
passwordField.send_keys(password)
passwordField.send_keys(Keys.RETURN)
#Finished logging in. now at
time.sleep(3)
encodedTag = urllib.parse.quote(tagName) #普通にURLに日本語は入れられないので、エンコードする
encodedURL = tagSearchURL.format(encodedTag)
print("encodedURL:{}".format(encodedURL))
browser.get(encodedURL)
#Finished tag search. now at https://www.instagram.com/explore/tags/%E8%AA%AD%E5%A3%B2%E3%83%A9%E3%83%B3%E3%83%89/?hl=ja
time.sleep(3)
browser.implicitly_wait(10)
#写真を取得してクリックする
mediaList = browser.find_elements_by_css_selector(mediaSelector)
mediaCounter = len(mediaList)
print("Found {} media".format(mediaCounter))
for media in mediaList:
media.click()
# 次へボタンが表示されるまで
while True:
try:
time.sleep(3)
browser.find_element_by_xpath(likeXpath).click()
browser.implicitly_wait(10)
likedCounter += 1
print("liked {} of {}".format(likedCounter,mediaCounter))
browser.find_element_by_css_selector(nextPagerSelector).click()
except:
break #もう次へボタンが存在しない場合、エラーをはくのでそこで終了
break #for文自体も終了させる
print("You liked {} media".format(likedCounter))
ご依頼について
スクレイピングツール欲しい方は、@never_be_a_pmにご連絡お願いします。2017-12-11
【Python】スクレイピングができるウェブサイトを作ってみた (開発環境編)
Web上でスクレイピングし、CSVにエクスポートできるツールを作ります

メルカリのAPI的なもの作ってみました。
- メルカリでほしい商品名を検索欄に入れる
- メルカリのデータを取得
- CSVでダウンロードできる
みたいなものです。とりあえずローカルから動かしているので、まだディプロイしていません。次に本番環境で動かしてみようとは思いますが、あまりメルカリさんに迷惑をおかけすると申し訳ないので、起動時間も一時的にしておきます。
#Flask— DAI (@never_be_a_pm) December 9, 2017
メルカリで商品情報を取得するフロントエンド部分を作成。取得したいキーワードを入れると、バックエンドでメルカリから自動でデータを取得し、CSV形式にエクスポートしてくれる仕組み。ディプロイできたら、スクレイピングの汎用ツールできる。 pic.twitter.com/MECQr238lX
2017-11-25
【Python】SEO対策向けの共起語取得ツールを作ってみた Selenium + Janome
SeleniumとJanomeで無理やり共起語取得ツールを作ってみた
自社の記事を検索上位に挙げるために必要な、検索最適化(SEO)。この検索最適化の要素の一つに、「共起語」の発生数というものがあるらしいです。
簡単に言うと、「Python 機械学習」と検索したときに、その関連する言葉が記事にたくさん入っていることが、検索上位の要因となっているという話です。
そこまでSEOに詳しくないので、詳細はこちらの記事にお任せします。
共起(きょうき)は、ある単語がある文章中に出たとき、その文章中に別の限られた単語が頻繁に出現すること。日本語の例では「崩御する」という単語に「天皇が」という言葉が多く用いられることや、単に他動詞には「を」が、「行く」には目的地を示す「に」が頻出することが挙げられる。(共起語の意味とは何?SEO効果があるのか? | アフィリエイト初心者でも稼げるネットビジネスブログ)
順位を上げたいページ(ページA)に、そのページで狙っているキーワード(キーワードA)の共起語(キーワードB)を加える。
キーワードBをアンカーテキストにして、キーワードBについて書いてあるページ(ページB)にリンクを張る。
この手法を実行した途端に、ありとあらゆるSEOを施策していたのに3ページ目より上に上げられなかったページAがキーワードAの検索で2位に来たそうです。「共起語SEOをもう一度解説してみる」
ということで、この共起語を見つけたいのですが、実際検索上位でどのような言葉がいくつ入っているのかがわかれば、逆算して「この単語とこの単語をいくつ出現させれば、検索上位を取れるのか」ということがわかります。そうすると、共起語取得ツールがあれば企業のWeb集客としても、非常に便利そうです。ということで、作ってみました。
2017-11-18
【Python】SeleniumでゴリゴリFacebook認証する
FacebookにSeleniumで無理やりログイン

Facebook認証を行っているWebアプリでWebスクレイピングを行おうとした時のメモ。
Facebookにログインしないと、データがとれないので、なんとかFacebookアプリにログインする方法を考えた。
普通はAPIになんらかのPOSTリクエストをして認証するのが大半だが、Selenium一発芸しか使えないので、無理やりブラウザ操作でFacebookにログインしてみた。
ソースコード
#1 Facebookにログインするメソッド
Facebookのメールアドレスとパスワードを引数をとって、Facebookにログインする。
def facebookLogin(email, password):
#1-1 Facebookログインが求められる、Webページにアクセスする
引数にFacebookアプリログイン画面のURLを入れるbrowser.get("ログインしたいFacebookアプリのURL")
#1-2 フォームにE-mailとパスワードを入れる
.find_element_by_css_selectorで、引数に入力したいフォームのIDを指定する。
send_keysの引数には、もともと入れていたemailアドレスが入力される。同様にパスワードも。
#1-2 値の入力 browser.find_element_by_css_selector("#email").send_keys(email) browser.find_element_by_css_selector("#pass").send_keys(password)
#1-3 パスワードの確認画面を閉じる
パスワードを入力すると、確認画面が送信ボタンの上に出てしまうので、関係ないほかのの部分をクリックすることによって消す。
#1-3 どこでもいいので、クリックしないと送信ボタンが押せないため、適当に押している browser.find_element_by_xpath('//*[@id="email_container"]/div/label').click() time.sleep(2)
#2 ログインメソッドを実行
#1で作成したメソッドを利用して、ログインする
facebookLogin(email, password)
全体のコード
facebookLogin.py
import os
from selenium import webdriver
import pandas
import time
browser = webdriver.Chrome(executable_path='/mnt/c/workspace/pydev/chromedriver.exe')
email = "FACEBOOKのメールアドレス"
password = "FACEBOOKのパスワード"
#1
def facebookLogin(email, password):
#1-1 最初にPairsのFacebook認証を済ませる
time.sleep(2)
browser.get("ログインしたいFacebookアプリのURL")
#1-2 値の入力
browser.find_element_by_css_selector("#email").send_keys(email)
browser.find_element_by_css_selector("#pass").send_keys(password)
#1-3 どこでもいいので、クリックしないと送信ボタンが押せないため、適当に押している
browser.find_element_by_xpath('//*[@id="email_container"]/div/label').click()
time.sleep(2)
browser.find_element_by_xpath('//*[@id="u_0_0"]').click()
time.sleep(4)
#2
if __name__ == '__main__':
facebookLogin(email, password)
2017-11-03
PythonからWordpressに自動投稿するスクリプトを作りました。

PythonからWord Pressに自動投稿するスクリプトを作りました。
環境
- Cloud9
- Python3
- PhontomJS *
- Selenium *
アルゴリズム
- ワードプレスのログイン画面に移動
- IDとパスワードを入力
- 送信ボタンを入力
- 新規投稿画面に移動
- タイトルと内容を入力
- 下書き保存をクリック
スクリプト
from selenium import webdriver #seleniumのimport
import time
browser = webdriver.PhantomJS()
loginURL = "http://yoursite.com/wp/wp-login.php" #yoursite.comにはあなたのサイトのアドレスを書いてください
browser.get(loginURL)
time.sleep(3)
print(browser.title) # "あなたのサイト名 ‹ ログイン"と表示される
#sign-in
username = "" #あなたのユーザー名を入れてください
password = "" #あなたのパスワードを入れてください
browser.find_element_by_css_selector("#user_login").send_keys(username)
browser.find_element_by_xpath("//*[@id='user_pass']").send_keys(password)
browser.find_element_by_css_selector("#wp-submit").click()
time.sleep(3) # waiting for sign in
print(browser.title) #"ダッシュボード ‹ あなたのサイト名 — WordPress"と表示される
#post
browser.get("http://yoursite.com/wp/wp-admin/post-new.php")
time.sleep(3) # waiting for sign in
print(browser.title) #"新規投稿を追加 ‹ あなたのサイト名 — WordPress"と表示される
title = "Test"
content = "test post"
browser.find_element_by_css_selector("#title").send_keys(title)
browser.find_element_by_css_selector("#content_ifr").send_keys(content)
browser.find_element_by_css_selector("#save-post").click
time.sleep(3) #waiting for post
これで投稿の下書きが完成します。

その他
今回はただポストするだけなのですが、ほかのサイトからとってきた複数のデータをfor文で回して自動生成とかも余裕でできそうなので、時間があるときにやってみます。
2017-10-08
【Python】Webスクレイピングチュートリアル -「次へ」ボタンが存在するページをすべて取得する場合 -
PythonのSeleniumを利用して、「次へ」ボタンが存在するページをすべて取得する方法を解説します。
目次
- 挙動を確認する
- 日本語でアルゴリズムを考える
- 実装する
- サンプルコード
2017-10-07
【Python】Webスクレイピングチュートリアル -ログインが必要なサイトの場合-

PythonのSeleniumを利用して、ログインが必要なサイトにアクセスし、データを取得する方法を解説します。
目次
- はてなブックマークにログインしてみる
- ログインページに移動する
- ログインページのフォームのid, class, もしくはxpathを取得
- データの挿入
- フォームの送信
- ログイン移動確認
はてなブックマークにログインしてみる
まず、はてなブックマークのログインページにアクセスしますと、このような画面になっています。

処理の流れとしては、こちらに
- 自分のメールアドレスを入力
- パスワードを入力
- 送信ボタンをクリックする
というのを、Webスクレイピングで実行します。さらにログイン後自分のプロフィールアドレスに行き、自分のアカウント情報が取得できるかどうか確認します。
もしログインしていない状態で、そのページに行くと、ログインページに移動されます。ちゃんとログインできていると、プロフィールページに移動されます。それでは、実際にやってみましょう。
ログインページに移動する::browser.get(url)
まず最初に、seleniumをimportします。
from selenium import webdriver
次に、webdriverという仮想のブラウザを呼び出します。
browser = webdriver.PhantomJS()ログイン先のURLをセットします。
loginUrl= "https://www.hatena.ne.jp/login"そして、そのページにWebdriverをアクセスさせます。
browser.get(loginUrl)
次に、自分のメールアドレスと、パスワードを入力します。
username = "あなたのメールアドレス"
password = "あなたのパスワード"
ログインページのフォームのid, class, もしくはxpathを取得::find_element_by_xpath()
で、今度はそのユーザー名と、パスワードを入力するところを指定する必要があるので、再度ログインページへアクセスし、F12ボタンを押します。そうするとこんな画面になると思います。
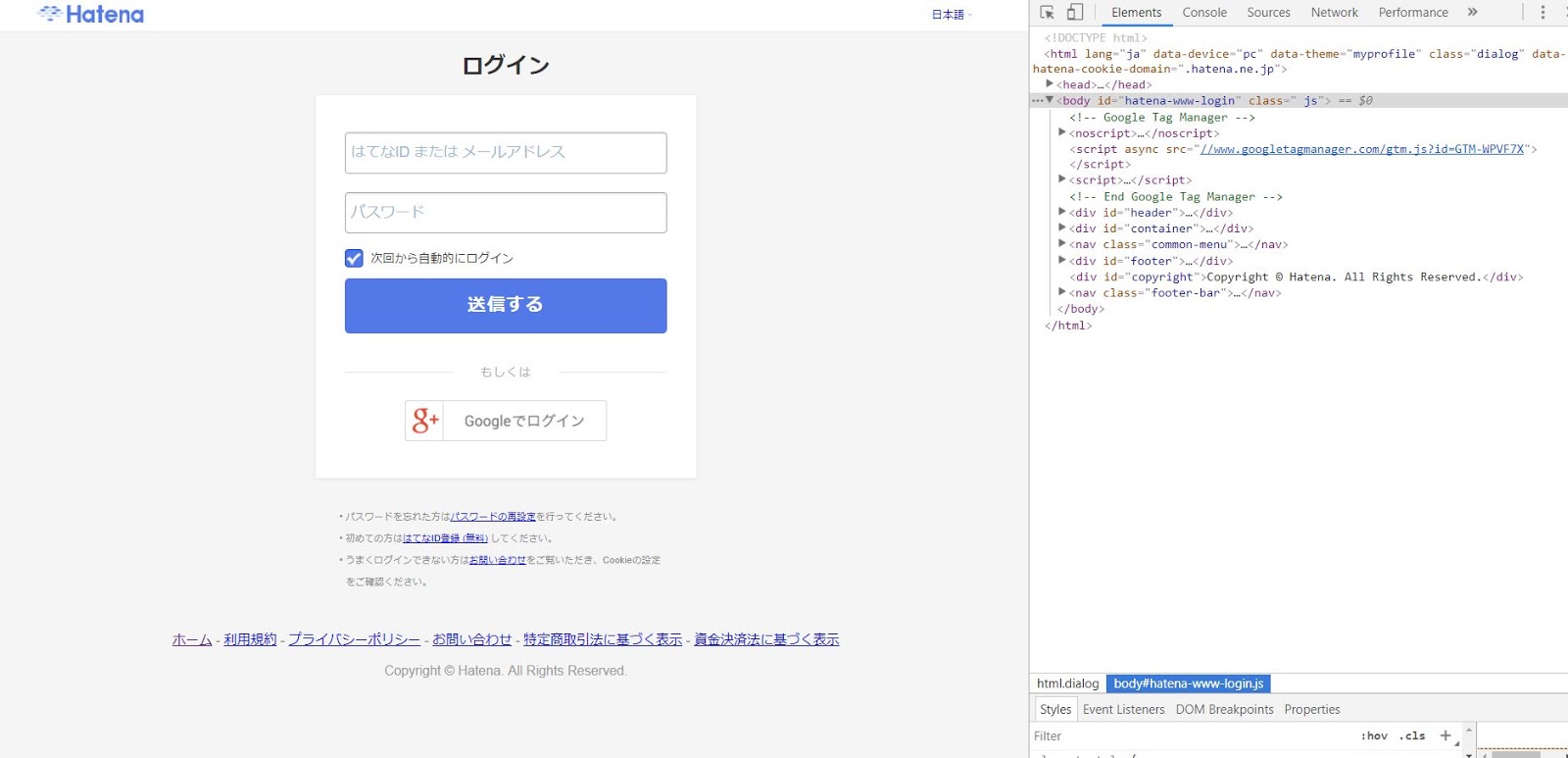
あとは、下のGIFのように、各値のclass、もしくはidを取得するか、xpathを取得してください。今回の場合は、xpathを取得します。

取得したユーザー名のXpathは、//*[@id='login-name']だったので、このように場所を指定してあげます。
userNameField = browser.find_element_by_xpath("//*[@id='login-name']")
データの挿入::send_keys()
そして、そのuserNameFieldに、usernameを入れてあげます。
userFameField.send_keys(username)
同様にパスワードもですね。
passwordField = browser.find_element_by_xpath("//*[@id='container']/div/form/div/div[2]/div/input")
passwordField.send_keys(password)
フォームの送信::click()
これで値が入るので、「送信する」ボタンのXpathを取得します。
submitButton = browser.find_element_by_class_name("submit-button")
submitButton.click()
ログイン移動確認::browser.title
これで、ログインが完了されるはずです。ログインが完了されていれば、プロフィールページに移動すると、自分のユーザー名が表示されたページに移動するはずです。
profile = "profile.hatena.ne.jp"そして、このページのタイトルを表示します。
browser.get(profile)
browser.title
これで自分のユーザー名が入ったページが表示されれば、成功です。おめでとうございます!最終的には、以下のようなコードとなります。
from selenium import webdriver
browser = webdriver.PhantomJS()
loginUrl= "https://www.hatena.ne.jp/login"
browser.get(loginUrl)
username = "あなたのメールアドレス"
password = "あなたのパスワード"
userNameField = browser.find_element_by_xpath("//*[@id='login-name']")
userFameField.send_keys(username)
passwordField = browser.find_element_by_xpath("//*[@id='container']/div/form/div/div[2]/div/input")
passwordField.send_keys(password)
submitButton = browser.find_element_by_class_name("submit-button")
submitButton.click()
profile = "profile.hatena.ne.jp"
browser.get(profile)
browser.title
最後に
ここまでで、よくわからなかった場合は、以下のチュートリアルにそって進めてみてくださいね!
Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう -
Python データアナリティクス入門マニュアル Webスクレイピングを、プログラミングを学んだことのない人向けに0から解説するマニュアルです。何から学ぶべきか、環境構築はどうするかからはじまって、Webスクレイピング、データの前処理、そしてデータビジュアライゼーションまでを丁寧に解説します。 ...
また、PythonのSeleniumのドキュメンテーションには、さらに便利なメソッドが存在するので、見てみてくださいね!
Selenium with Python - Selenium Python Bindings 2 documentation
This is not an official documentation. If you would like to contribute to this documentation, you can fork this project in Github and send pull requests. You can also send your feedback to my email: baiju.m.mail AT gmail DOT com. So far around 40 community members have contributed to this project (See the closed pull requests).
>Python データ分析入門マニュアルに戻る
■入門マニュアル
〇 Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう
〇 Pythonの環境構築でもう悩まない!初心者でも絶対にできるクラウドを使った環境構築方法!
■スクレイピング
〇 Python初心者が3カ月でWebスクレイピングができるようになるために必要な知識
〇 【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~
■データビジュアライゼーション
〇 【Python初心者向け】データの取得・操作・結合・グラフ化をStep by Stepでやってみる - pandas, matplotlib -
■定期処理
〇 【Pythonで定期処理】 Cloud9を利用して、Seleniumでherokuから定期実行する
〇 Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう
〇 Pythonの環境構築でもう悩まない!初心者でも絶対にできるクラウドを使った環境構築方法!
■スクレイピング
〇 Python初心者が3カ月でWebスクレイピングができるようになるために必要な知識
〇 【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~
■データビジュアライゼーション
〇 【Python初心者向け】データの取得・操作・結合・グラフ化をStep by Stepでやってみる - pandas, matplotlib -
■定期処理
〇 【Pythonで定期処理】 Cloud9を利用して、Seleniumでherokuから定期実行する
Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう -
Python データ分析入門マニュアル
Webスクレイピングからデータビジュアライゼーションを、プログラミングを学んだことのない人向けに0から解説するマニュアルです。何から学ぶべきか、環境構築はどうするかからはじまって、Webスクレイピング、データの前処理、そしてデータビジュアライゼーションまでを丁寧に解説します。
すべてのカリキュラムが一カ月で終わるようにしています。過去記事にまとめてあるので、それを順に追って行ってもらう形になります。
目次
- 基礎的な統計の知識をつけよう(0-2日)
- プログラミングの基礎を学ぼう:HTML・CSS・Javascirpt・Python (10日)
- Cloud9をセットアップしよう(Seleniumと定期実行環境の設定) (2日)
- Cloud9とJupiterNotebookで、Webスクレイピングとデータ分析をしてみよう (5日)
- PythonでAPIを利用しよう(3日)
- Botを作ろう(3日)
- 実際にAPIやWebスクレイピングを利用しデータ分析をやってみよう(5日)
2017-10-06
Python初心者が3カ月でWebスクレイピングができるようになるために必要な知識
こんにちは、Daiです。最近Pythonが人気ですが、機械学習には手を出せない、とはいえプログラミングの挨拶プログラムを作るのには飽きた!みたいな人って結構多いのでじゃないでしょうか。
最近、Qiitaという技術掲示板でも、PythonのWebスクレイピングの方法を解説する記事が人気でしたが、まったくの初心者にはどうすればいいかわからないというレベル間だったと思います。そこで、今回はプログラミング初心者の人でも、何を学べばWebスクレイピングをPythonでできるようになるか、解説したいと思います。
2017-10-01
【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~

この数年間、Pythonの人気が高まっています。Googleトレンドによると、Pythonの検索流入数は、この10年間で2倍近くになりました。特にグラフから見ると、だいたい2015年ぐらいからPythonの検索数は増えている模様です。
さて、この数年間で、Pythonがどのような言語として扱われ、どう変化してきたののでしょうか。Webスクレイピング→データ収集→整形→分析を行い、今回は、2006年度から2017年度までのはてなブックマーク上のPython記事で、50ブックマーク以上の記事をすべて取得することによって、時代によってブックマークされやすいPython記事を分析してみようと思います。
そのためには、(1)データの取得と(2)データの分析、そして最終的に(3)結果のレポートにわけて、分析を進めていきたいと思います。
目次
- データ分析のケース
- 環境
- 1. データの収集: SeleniumとPandasでスクレイピング結果をCSVに書き込もう!
- 2. データを分析しよう: Jupiter NotebookとPandasで対話的な分析!
- 3. データ分析結果をレポートする
- 4. 最後に
2017-09-24
【Python】Slack Botの作り方まとめ - Webスクレイピング・定期実行の合わせ技 -
#背景
ちはっす。DAIです。
会社の同僚と自宅でよく作業会をやっています。音楽聞いて、料理食べて、あとはただコツコツとみんなでそれぞれが勉強するだけなのですが、とてもQOLが高いです。
#やりたいこと
チケットを譲ってくれる人を見つけられるサイトがあるそうです。ここの最新情報を毎日自動でSlackで更新するようにします。
おけぴチケット救済サービス(定価以下限定チケット掲示板)
ミュージカルや演劇、劇団四季、宝塚歌劇、クラシック、コンサート、ライブ等の空席救済を目的とした観劇鑑賞生活応援サイトです

そのサイトでは、自分の見たいタイトルの舞台の名前を入れると、そのチケットを渡してくれる人を探すことができるそうなのですが、毎日検索して確認するのが面倒だそうなので、これを毎日プログラムが取得して、まとめたデータをSlackに通知してくれたら便利じゃね?ってはなしになり、作ってみました。
スクレイピングをPythonでするときは、Cloud9・Selenium・Herokuで決まり!誰でもできるスクレイピングマニュアル

こんにちは、DAIです。
さて、Pythonでスクレイピングする際に必要になってくるSelenium。そしてこのスクレイピングプログラムを定期実行したい。これをCloud9上で実行したい人も多いのではないでしょうか。
昨日、久しぶりにCloud9上でSeleniumの環境構築を行ったのですが、どうも毎回調べてはエラーを繰り返して・・・・という感じだったので、一回Cloud9上でSeleniumの環境構築し、ディプロイするまでをまとめておきたいと思います。だれでも5分以内に同じ動作で、Cloud9上でSeleniumが利用できる環境をセットアップできることを目指します。
#対象者
・HTML/CSS/Javascript/jQuery/Git/Python基礎を学習したことがある人(そうでない人は、Pythonでスクレイピングとか、Slack自動更新とかやってみたい人が学ぶべき5つの言語を参照してから、また挑戦してみてください)
#TODO
- Cloud9でPython環境のセットアップ
- Cloud9アカウントの作成とPython環境のセットアップ
- Python2から3へのバージョンアップ
- $ sudo mv /usr/bin/python /usr/bin/python2
- $ sudo ln -s /usr/bin/python3 /usr/bin/python
- $ python --version
- Githubに登録し、新しいレポジトリの作成
- Bottleのインストールとサンプルプログラムの実行
- sudo pip install bottle
- すべてのファイルの削除
- Herokuアカウントの作成とログイン
- requirement.txtの作成と編集
- pip freeze | grep bottle > requirements.txt
- echo web: python app.py > Procfile
- echo "python-3.6.2" > runtime.txt
- Herokuにディプロイし起動
- git init
- git add .
- git commit -am 'initial commit'
- git remote add origin git@github.com:[username]/[gitname].git
- git push origin master
- heroku login
- heroku create [herokuName]
- git push heroku master
- xxx.herokuapp.com/hello/へアクセス
- Seleniumのインストール
- sudo pip install selenium
- requirement.txtにselenium==2.45.0
- サンプルコードの作成+コードのプッシュ
- seleniumTest.pyを作成
- コードのコピペ
- git add .
- git commit -am 'added'
- git push heroku master
- HerokuにPhantomJSのセットアップと、パスの設定
- heroku buildpacks:add --index 1 https://github.com/stomita/heroku-buildpack-phantomjs
- git push heroku master
- 稼働テスト:グーグルのタイトルを表示してみる
- heroku run python seleniumTest.py
- 定期実行プログラムを組む
- heroku addons:create scheduler:standard
- heroku addons:open scheduler
- 実行コマンドと実行間隔を設定
2017-09-09
『Pythonによるスクレイピング&機械学習 開発テクニック』レビュー
『Pythonによるスクレイピング&機械学習 開発テクニック』を読了しました。

『Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう』について、レビューします。
Amazonの紹介によると
機械学習の重要性は、日々高まっているものの、いったいどのように実務に取り入れたら良いのかという声を聞くようになりました。
本書では、実際にデータの集め方から、機械学習を活用するところまで、実践的なPythonのサ ンプルコードで紹介します。
と書いてありました。Pythonを利用して、データを集めて整理するところから始められる参考書はなかなかなかったので、これは!と思い『Pythonによるスクレイピング&機械学習 開発テクニック』を購入しました。実際に買ってみて試したうえでレビューしていきたいと思います。

Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう
posted with amazlet at 17.09.08
クジラ飛行机
ソシム
売り上げランキング: 13,688
ソシム
売り上げランキング: 13,688
目次
- 買った経緯
- こんな人におすすめ
- 本の内容
- できるようになったところ
買った経緯
私はもともと趣味でエクセルを使って、教育のオープンデータ分析をしていたのですが、どうしてもHTMLからデータを取ってくるのが面倒で、調べてみるとスクレイピングという技術を使えばわりとできそうだとわかりました。スクレイピングについてはこちら
「Webスクレイピングとは何ぞや?」という疑問が浮かんできたので調べてみた。 - おしい県でWebに携わって働く人のブログ
最近よく聞く、、、わけではありませんが、なんとなく自分の中で「Webスクレイピング」について知りたくなったので、ググったりして調べてみました。
調べてみるとデータを扱ったり機械学習に関してはPythonをよく使うみたいで、ちょうど両方扱っているみたいなので、購入しました。
ちなみにこの本を購入した時点では、ノンプログラマではありません(*HTML、CSS,
JS、jQuery、Rubyを1年学習済み)でしたが、Pythonは書いたことがありませんでしたので、ProgateのPythonコースと、ドットインストールのPythonコースを全部学んで、キャッチアップしてからスタートしました。
Progate(プロゲート) | Learn to code, learn to be creative.
Progateはオンラインでプログラミングを学べるサービスです。プログラミングを学んでWEBアプリケーションを作ろう。
Python 3入門 (全31回)
データ解析や機械学習などにも利用される、シンプルなオブジェクト指向型言語であるPythonについて見ていきます。
こんな人におすすめ
上記に書いたような、データサイエンス・機械学習に興味があるような人や、Pythonを使って何かやってみたいという人にはおすすめです。実際まったくの初心者でも、コードを移していくとスクレイピングできるコードを自分で作ったりできるようになります。
ただし、全くのプログラミング初心者では難しいので、基本的なHTML、CSS、Javascript、jQueryが理解できる程度の知識が必要です。
というのも、どうしてもスクレイピングを利用するとなると、HTMLの力が知識が前提となってしまうからです。それを操作するCSS、Jsの知識は必要となります。無料でできるので、さきほどのProgateやドットインストールでキャッチアップしましょう。
また、僕のように機械学習エンジニアに興味があるくらいのレベルであれば、実際にコードを書いて学ぶことができるのでおすすめですが、機械学習はマシンのスペックゲーになることが多かったので、機械学習をちゃんとやりたい場合はちゃんとしたマシンを用意しないとだめですね。僕はノートパソコンで試したら死亡しました。
本の内容
目次はこんな内容となっています。(一部省略)
- クローリングとスクレイピング
- データのダウンロード
- Beautiful Soupでスクレイピング
- CSSセレクタについて
- リンク先をまるごとダウンロード
- 高度なスクレイピング
- ログインが必要なサイトからダウンロード
- ブラウザを経由したスクレイピング
- スクレイピング道場
- Web APIからのデータ取得
- Cronと定期実行なクローリング
- データソースと書式・設定
- テキストデータとバイナリデータ
- XMLの解析
- JSONの解析
- YAMLを解析する
- データベースについて
- 機械学習
- 機械学習とは
- 機械学習のはじめの一歩
- 画像の文字認識
- 外国語文書の判定
- サポートベクターマシンとは
- ランダムフォレストとは
- データの検証方法について
- 深層学習に挑戦してみよう
- 深層学習とは何か
- TensorFlowのインストール
- JupyterNoteBookのすすめ
- TensorFlowの基本をおさえよう
- TensorBoardで可視化しよう
- TensorFlowで深層学習に進もう
- Karasでもっとらくに深層学習をしよう
- テキスト解析とチャットボットの作成
- 日本語解析(形態素解析)について
- Words2Vecで文章をベクトル変換しよう
- ベイズの定理でテキストを分類しよう
- MLPでテキスト分類しよう
- 文書の類似度をn-gramで調べよう
- マルコフ連鎖やLSTMで文書を作成しよう
- チャットボットの作成
- 深層学習を実践してみよう
- 類似画像の検出をしよう
- CNNでCaltech101の画像分類をしよう
- 牛丼屋のメニューを画像判定しよう
- OPEN CVで顔認識
- 画像OCR・連続文字認識に挑戦しよう
- APPENDIX 作業の準備と環境構築
- Dockerで環境構築しよう
- Python + Anacondaで環境を整える
Pythonの環境構築から、スクレイピング、データの操作、APIの利用、機械学習等データサイエンスの基礎部分に関する内容が、ソースコードとともにかなり丁寧に解説されています。Amazonの本の紹介でもあった通り、Web上のデータをスクレイピングし、データベースに格納、必要なデータを機械学習でコーディングするという一連の作業がこの本を通して学べたと思います。
また、Python初心者も想定して、親切にもWindows、Mac両方で環境構築の説明ランがあります。WindowsとMacの両方の環境構築方法が記述してあります。なので、初心者でも十分進められると思います。最悪環境構築につまったら、Cloud9というWeb上で環境構築を行えるプラットフォームを利用すればなんとかなります。
たった3分で?!初心者向けPython開発環境構築3ステップ | 侍エンジニア塾ブログ | プログラミング入門者向け学習情報サイト
こんにちは!インストラクターの井上(@InoIno_iesa )です。 Python学習したい!そう思っても プログラミングを始めるところにすらたどり着けない という方もいらっしゃるかと思います。 実際、プログラミングの「環境構築」は中級者でも数時間・数日はまってしまう可能性のあるものです。 しかし、そんな 環境構築を一瞬で終わらせる方法 があります! ...
できるようになったこと、この本の知識を活かして試したこと
この本を使ってできるようになったこととしては、seleniumを利用した基礎的なスクレイピングと、APIの利用、pandasとsqliteを利用してデータベースをいじり、matliolibやnumpyでグラフ描写する力、cronを利用してスクレイピングを自動で定期実行などですね。
実際に試したこととしては、TinderのAPIをPython上で利用して、Facebook上の既婚者が利用していないか調べたり、そういう情報をデータベースに格納したりとか....
PythonでTinderのAPIをいじる
PythonでTinderのAPIを利用する TinderにはAPIがあるそうなので、さっそく利用してみた。 PythonはCloud9というクラウドで環境構築してある。 TinderのAPIを使うために必要なのはFacebookのアクセストークンと、Pynderというモジュール。 Pynderを準備 pythonでapiをいじるためのpynderをinstall $ sudo pip install pynder インストールされたみたい。 インストールされたか確認 apiいじるコードをgithubからコピペする https://github.com/charliewolf/pynder import pynder session = pynder.Session(facebook_id, facebook_auth_token) session.matches() # get users you have already been matched with session.update_location(LAT, LON) # updates latitude and longitude for your profile session.profile # your profile.
PythonでTinder APIを使ってネトストとサイバーナンパ師やってみた
Python TinderのAPI Pynderを利用する こんにちは。突然ですが、ナンパしたい。僕は陰キャラなので、歌舞伎町でナンパに繰り出すことなんてできない。 そういえば前回、 PythonでTinderのAPIをいじる で書いた通り、PythonでTinderのAPIをいじれた。原理的には自分のアカウントのFacebook access ...
pythonでsqlite3を利用してデータを挿入する
受験・教育学、心理学、社会学、プログラミング・書評とかで記事書いてます。
Cloud9上で実装したPythonスクリプトをHerokuにディプロイしてして定期実行する手段を生み出したり...
【Pythonで定期処理】 Cloud9を利用して、Seleniumでherokuから定期実行する
Python Cloud9を利用して、定期処理をherokuから行う Cloud9というIDEを利用して、PythonからSeleniumを利用し、あるサイトでいいねを自動化するプログラムを作った。 これを定期実行を行いたい。検索してみると、crontabを使えば定期実行ができるようだが、cloud9上では実行できないらしい。 ほかの代替案を考えたとき、 heroku ...
定期実行プログラムをかけるようになったから、Twitterのフォロワーを自動いいねしたりするプログラムを書いたり
【Python twitter】tweepyを利用してlike、follow、removeを実装したbotを作る
なぜやるか ・ブロガーをやっているので、自分のファンになってくれる可能性があるユーザーをフォローしたい。 ・そのユーザーのコメントにいいねして、後で見返したい。フォローしてきたスパムアカウントはりむーぶしたい。 ・毎日自分の手でやるのは社会人になってしまったので時間がない。ということで自動化したい。 - python 3 - Cloud9を利用 - すでにherokuにpythonプロジェクトをdeploy済みです。 deployまでは下の記事を参考にしてください! やりたいこと 0. とりあえずtwitter apiを使ってログインしてみる 1. それぞれのユーザー名を取得し、そのユーザーのコメントにいいねとフォローを行う 2. 自分のタイムラインからツイートを10つ取得し、上から下までいいねを行う 3.フォロワー数が100未満のユーザーはすべてりむーぶする 4. heroku schedulerを利用して、上記の機能を定期処理で自動化する 0. pythonのtwitter apiであるtweepyを利用してログインしてみる APIを利用して、ツイッターからの情報とるためには、最初に情報を準備しておかなければならない。詳しいことはこの記事に書いてあるので、参照してほしい。 # Tweepyライブラリをインポート import tweepy # 各種キーをセット CONSUMER_KEY = 'xxxxxxxx' CONSUMER_SECRET = 'xxxxxxxx' ACCESS_TOKEN = 'xxxxxxxx' ACCESS_SECRET = 'xxxxxxxx' auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET) #APIインスタンスを作成 api = tweepy.API(auth) PythonでTwitterを使う 〜Tweepyの紹介〜 http://kivantium.hateblo.jp/entry/2015/01/03/000225 Tweepyでpythonについて呟いたアカウントをフォローしまくってみた - 駆け出し眼鏡のプログラミング道場 http://taikomegane.hatenablog.jp/entry/2017/07/08/151110 1.
わりとやりたいことができるようになった感じですね。
アマゾンで最近見たら書店より少し安くなっていたので、
- Pythonに興味がある
- データサイエンスに興味がある
- しかもなんか意味あることを実践的にやりたい
という人のは強くおすすめします!
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう
posted with amazlet at 17.09.08
クジラ飛行机
ソシム
売り上げランキング: 13,688
ソシム
売り上げランキング: 13,688
Amazon.co.jpで詳細を見る
>Python データ分析入門マニュアルに戻る
>Python データ分析入門マニュアルに戻る
Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう -
Python データ分析入門マニュアル Webスクレイピングからデータビジュアライゼーションを、プログラミングを学んだことのない人向けに0から解説するマニュアルです。何から学ぶべきか、環境構築はどうするかからはじまって、Webスクレイピング、データの前処理、そしてデータビジュアライゼーションまでを丁寧に解説します。 ...
■入門マニュアル
〇 Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう
〇 Pythonの環境構築でもう悩まない!初心者でも絶対にできるクラウドを使った環境構築方法!
■スクレイピング
〇 Python初心者が3カ月でWebスクレイピングができるようになるために必要な知識
〇 【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~
■データビジュアライゼーション
〇 【Python初心者向け】データの取得・操作・結合・グラフ化をStep by Stepでやってみる - pandas, matplotlib -
■定期処理
登録:
投稿 (Atom)
-
相関分析・重回帰分析・クロス集計の結果を、英語でレポートしよう! 英語で卒論書いていたのですが、統計のレポートの際に、英語のボキャブラリーに慣れておらず、いろいろ調べながらやって時間が無駄にかかりました。テンプレがなかなか見つからなかったので、まとめておきます。 ...
-
 社会人になると、建設的な会話ができる人とそうでない人に大きく分かれますよね。僕がいろいろな人と話していて、この人建設的な会話できる人だなぁと思った人と、そうでない人を思い出しつつ、 建設的(constructive) な会話と、そうでない会話の違い が何かを考えてみました...
社会人になると、建設的な会話ができる人とそうでない人に大きく分かれますよね。僕がいろいろな人と話していて、この人建設的な会話できる人だなぁと思った人と、そうでない人を思い出しつつ、 建設的(constructive) な会話と、そうでない会話の違い が何かを考えてみました... -
 ICU生の偏差値は? こちらの記事は、ICUの偏差値について解説します。 ICUの受験対策はどうすればいいの?受験科目から、おすすめの受験対策方法をまとめてみた 【ICU生の特徴は?】現役ICU生100人に徹底調査した記事まとめ 【ICU生に聞い...
ICU生の偏差値は? こちらの記事は、ICUの偏差値について解説します。 ICUの受験対策はどうすればいいの?受験科目から、おすすめの受験対策方法をまとめてみた 【ICU生の特徴は?】現役ICU生100人に徹底調査した記事まとめ 【ICU生に聞い...
