PythonのSeleniumを利用して、「次へ」ボタンが存在するページをすべて取得する方法を解説します。
目次
- 挙動を確認する
- 日本語でアルゴリズムを考える
- 実装する
- サンプルコード
挙動を確認する
実際にはてなブックマークの検索ページに行きまして、「R」と検索してみてください。そうすると、以下のようなURLに飛びます。http://b.hatena.ne.jp/search/text?q=R
検索語句ですが、実は検索語句のtext?q=Rの中に、検索語句が含まれています。このように、q=[]の中に検索語句を入れれば、検索結果が取得できるようになるというわけです。
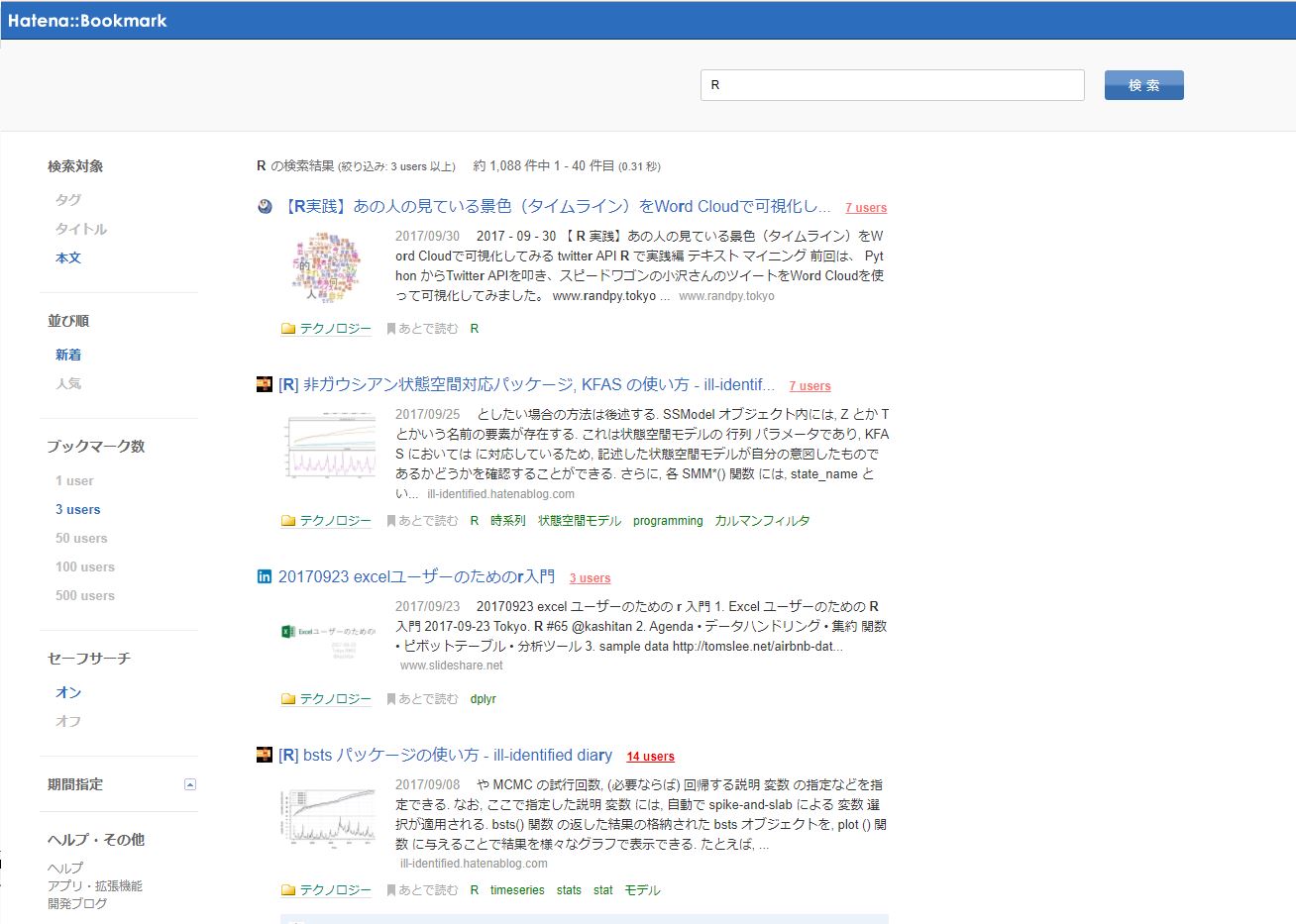
さて、次のページに移って、新たな情報を取得するので、ページ最下部へ行き、次の40件
というボタンを見つけます。そうすると、次の40件を取得してくれます。これを何度も繰り返すと、最後のページにつきます。そうすると、次の40件のボタンがなくなります。

次の40件のボタンのXpathを取得します。
こちらを、前の記事で紹介したように、xpathで位置を保存してください。
【Python】Webスクレイピングチュートリアル -ログインが必要なサイトの場合-
Pythonの Selenium を利用して、ログインが必要なサイトにアクセスし、データを取得する方法を解説します
日本語でアルゴリズムを考える
さて、これらの動作を実際のプログラミングに落とし込んでいくわけですが、日本語で一度アルゴリズムを考えていきます。
- 検索語句を格納する変数を用意する (例)query = "R"
- http://b.hatena.ne.jp/search/text?q=QueryとなるようなURLを用意する
- そのURLにアクセスする
- そのページに存在する各記事をXpathで複数取得する
- 記事からそれぞれ以下の情報を取得し、csvに追加する
- タイトル
- 作成日時
- ブックマーク数
- もし次の40件のボタンがあれば
- 次の40件ボタンをクリックし、ページの情報を再度printする
- もし次の40件のボタンがなければ
- 処理を終了する
実装する
まず、各モジュールをインポートします。
from selenium import webdriver #Seleniumを動かすもの
from pandas import * #CSVやデータを取り扱うもの
import time #処理を一度待つもの
そして、検索語句を設定し、そのページにアクセスします。
browser = webdriver.PhantomJS() # DO NOT FORGET to set path
query = "R"
url = "http://b.hatena.ne.jp/search/text?safe=on&q=" + query + "&users=50"
browser.get(url)
df = pandas.read_csv('trend.csv', index_col=0)
page = 1 #This number shows the number of current page later
もし、ページに「次の40件」ボタンが存在したときは、記事を取得し、存在しないときは処理を終わるようにします。
while True: #continue until getting the last page
if len(browser.find_elements_by_css_selector(".pager-next")) > 0:
print("######################page: {} ########################".format(page))
print("Starting to get posts...")
#get all posts in a page
posts = browser.find_elements_by_css_selector(".search-result")
:
else: #if no pager exist, stop.
print("no pager exist anymore")
break
次の40件ボタンが存在する場合、すべての記事を取得して、一つ一つ記事名(title)、作成日(date)、ブックマーク数(bookmarks)を取得し、pandasのSeriesオブジェクトの中に挿入し、そしてもともと定義しておいたdfというデータフレームに挿入します。これをすべてのページ内のすべての記事分行います。
posts = browser.find_elements_by_css_selector(".search-result")
for post in posts:
title = post.find_element_by_css_selector("h3").text
date = post.find_element_by_css_selector(".created").text
bookmarks = post.find_element_by_css_selector(".users span").text
se = pandas.Series([title, date, bookmarks],['title','date','bookmarks'])
df = df.append(se, ignore_index=True)
print(df)
これらの処理が終わったら、今度は下の「次の40件」のURLを取得し、次のページに移ります。なお、ページの移動の際には、はてなさんのサーバーを重くさせないように、10秒待つメソッドを実行します。
#after getting all posts in a page, click pager next and then get next all posts again
btn = browser.find_element_by_css_selector("a.pager-next").get_attribute("href")
print("next url:{}".format(btn))
browser.get(btn)
page+=1
browser.implicitly_wait(10)
print("Moving to next page......")
time.sleep(10)
かくして、記事名、更新日時、ブックマーク数を取得したテーブルが完成したので、csvに落とし込みます。
df.to_csv(query + ".csv")
print("DONE")
これで処理は完了します。
サンプルコード
完成したものをこちらに置いておきます。(ところどころ不必要なコードが書いてありますが、気にしないでください。)from selenium import webdriver
import requests # for slack
from pandas import *
import time
#Access to page
browser = webdriver.PhantomJS() # DO NOT FORGET to set path
query = "R"
url = "http://b.hatena.ne.jp/search/text?safe=on&q=" + query + "&users=50"
browser.get(url)
df = pandas.read_csv('trend.csv', index_col=0)
#Insert title,date,bookmarks into CSV file
page = 1 #This number shows the number of current page later
while True: #continue until getting the last page
if len(browser.find_elements_by_css_selector(".pager-next")) > 0:
print("######################page: {} ########################".format(page))
print("Starting to get posts...")
#get all posts in a page
posts = browser.find_elements_by_css_selector(".search-result")
for post in posts:
title = post.find_element_by_css_selector("h3").text
date = post.find_element_by_css_selector(".created").text
bookmarks = post.find_element_by_css_selector(".users span").text
se = pandas.Series([title, date, bookmarks],['title','date','bookmarks'])
df = df.append(se, ignore_index=True)
print(df)
#after getting all posts in a page, click pager next and then get next all posts again
btn = browser.find_element_by_css_selector("a.pager-next").get_attribute("href")
print("next url:{}".format(btn))
browser.get(btn)
page+=1
browser.implicitly_wait(10)
print("Moving to next page......")
time.sleep(10)
else: #if no pager exist, stop.
print("no pager exist anymore")
break
df.to_csv(query + ".csv")
print("DONE")
>Python データ分析入門マニュアルに戻る
■入門マニュアル
〇 Python データ分析入門マニュアル - 実例を使ってWebスクレイピングからデータビジュアライゼーションまでやってみよう
〇 Pythonの環境構築でもう悩まない!初心者でも絶対にできるクラウドを使った環境構築方法!
■スクレイピング
〇 Python初心者が3カ月でWebスクレイピングができるようになるために必要な知識
〇 【Python】スクレイピング→データ収集→整形→分析までの流れを初心者向けにまとめておく ~Pythonに関するはてな記事を10年分スクレイピングし、Pythonトレンド分析を実際にやってみた~
■データビジュアライゼーション
〇 【Python初心者向け】データの取得・操作・結合・グラフ化をStep by Stepでやってみる - pandas, matplotlib -
■定期処理


