ココナラという、スキル売買サイト
従来の「どの企業に入るか」で自分の価値が決まっていた時代とは逆に、個人のスキルと信頼度で価値が決まってくる社会になってきました。
さて、実はこのスキルと信頼の二つのうち、スキルを売り買いできるサイトがあるのは、ご存知でしょうか。
ココナラというサービスです。
ココナラは、
知識・スキル・経験を売り買いできる
フリーマーケットです。(ココナラ公式)

このサービスでは、実際に自分の得意なスキルを販売することができます。クラウドソーシングとまったく逆の発想で、非常に面白いですね。例えば、このサイトの趣味・娯楽ページでは、こんなものが売られています。
- 耳コピして、ギターのタブ譜を売るサービス(1000円)
- ドラムの譜面の作成サービス(2000円)
- Webページのスクレイピング(2000円)

このように、今までは価値がつけられなかったスキルが、インターネットの力で価値化され、売買されているという面白い仕組みのサイトです。iOS、アンドロイドともにダウンロードできるようになっています。
1分以内に完了!無料会員登録はこちら
ココナラのデータをマイニングして「稼げるスキル」を掘り当てる
スキルの価値をもう少し踏み込んでみてみましょう。ココナラで売れるスキルはどのようなものがあるのでしょうか。
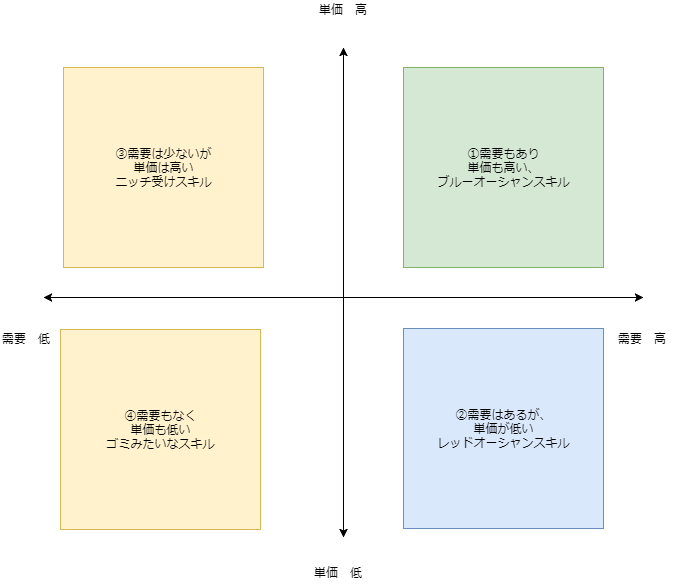
さてさて、このサイトをいろいろ見ていると、スキルによってはものすごく高い値段で売れているものもあれば、そうでないものもあります。4象限に分けると、
- 需要もあり、単価も高い、ブルーオーシャンスキル
- 需要はあるが、単価が低い、レッドオーシャンスキル
- 需要は少ないが、単価は高い、ニッチスキル
- 需要もなく、単価も低い、ゴミみたいなスキル
があると思われます。
手順
スクレイピング一発芸人なので、とりあえず今回は、ココナラの「趣味・娯楽」のスキルを可視化してみたいとおもいます。趣味でやっているようなことが、お金になったら普通に面白いですよね。
そのあと、適当に料理していこうかと思います。
スクレイピング
さきほどの「趣味・娯楽」ページにアクセスして、最後のページまでデータを抜き取り、さくっとCSVにしちゃいますと。持ってくるデータは、そのサービスの名前、内容、価格、いいね数です。
趣味・娯楽の相談・アドバイス | ココナラ
いいね数は、このサービスだとクリップの用に使われます。この数値の大きさを、需要としてみなします。(本当は購入数を見てもよいのですが、そうするとココナラさんにものすごくアクセスの負担をかけてしまいそうなんでやめました)ちなみにスクレイピングはPythonで書いています。
import sys import os from selenium import webdriver import pandas import time browser = webdriver.Chrome(executable_path='/mnt/c/workspace/pydev/chromedriver.exe') #1 args = sys.argv df = pandas.read_csv('default.csv', index_col=0) #3 browser.get("https://coconala.com/categories/8") #4 page = 1 #5 while True: #continue until getting the last page #5-1 if len(browser.find_elements_by_css_selector("a.next")) > 0: print("######################page: {} ########################".format(page)) print("Starting to get posts...") #5-1-2 time.sleep(5) posts = browser.find_elements_by_css_selector(".listContentBox") #ページ内のタイトル複数 print (len(posts)) #5-1-3 for post in posts: try: title = post.find_element_by_css_selector("a.js-service-view-tracker").text print(title) detail = post.find_element_by_css_selector("h3").text print(detail) #5-1-3-1 price = post.find_element_by_css_selector("strong.red").text print(price) #5-1-3-2 liked = post.find_element_by_css_selector("span.overlay").text print(liked) url = post.find_element_by_css_selector("a.js-service-view-tracker").get_attribute("href") se = pandas.Series([title,detail, price, liked,url],['title', 'detail','price','liked','url']) df = df.append(se, ignore_index=True) except: print("Error:Advertisement appeared.Skipping...") #5-1-4 page+=1 btn = browser.find_element_by_css_selector("a.next").get_attribute("href") print("next url:{}".format(btn)) browser.get(btn) print("Moving to next page......") #5-2 else: print("no pager exist anymore") break #6 print("Finished Scraping. Writing CSV.......") df.to_csv("output.csv") print("DONE")
こんな感じでデータが取れます。
— DAI (@never_be_a_pm) November 22, 2017
で、CSVをゲットしたので、分析してみましょう。
— DAI (@never_be_a_pm) November 23, 2017
Jupyter Notebookで分析だよぉ
はい、データ取ってこれたので、Jupyter Notebookで分析しますと。
とりあえずこれを使うためのライブラリをインストールしてと....
$ sudo pip3 install matplotlib $ sudo pip3 install pandas
ライブラリを入れて、CSVをひらき~の
import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv("output.csv",index_col=0) df.head()
そうするとこんな感じで出てくると。

サンプル数を見てみます。
print("number of samples:{}".format(len(df))) > number of samples:3838
おお、3868個も取れましたか。結構とれましたね。
それじゃ。とりあえず、要約統計量を出しましょう。まずはいいね数!
likes = df.likes likes.describe()#いいね数の要約統計量 > count 3838.000000 mean 3.718082 std 8.651673 min 0.000000 25% 0.000000 50% 1.000000 75% 3.000000 max 129.000000 Name: likes, dtype: float64
ええっと
- サンプル数:3838
- 平均いいね数:3.71
- 中央値が1いいね
- 最大値が129いいね
みたいですね。自分のサービスが3いいねつけば、上位25%の人気度にはなるみたいですね。一応箱ひげ図を出してみましょう。
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline plt.boxplot(likes) plt.title("boxplot on likes")

ん~外れ値ばっかりですね。ほとんどが10いいね以下で、めっちゃくちゃ人気のあるサービスが外れ値として、ぽつぽつといった感じですね。
お次はヒストグラムを出してみます。
plt.hist(likes) plt.title("Histgram on number of likes for each services") plt.xlabel("likes") plt.ylabel("count")
その結果がこちら。まあ、箱ひげ図のあたりで予想はついてたけど笑

さて、お次は価格を見ていきましょう。まずは要約統計量をと。
price = df.price #price行の取得 price.describe() #要約統計量 > count 3838.000000 mean 1189.942678 std 2147.574214 min 500.000000 25% 500.000000 50% 500.000000 75% 1000.000000 max 50000.000000 Name: price, dtype: float64
ふむふむ、
- 平均価格は1189円
- 最低価格が500円
- 第三四文位で1000円くらい
- 最大価格が50000円のようですね。
もう、見た感じまた安い値段に集中してそうなので、箱ひげ図をはしょってヒストグラムをみてみましょうと。
plt.hist(price) plt.title("Histgram on Price") plt.xlabel("price") plt.ylabel("count")

予想した通りになりました。
では、本題。(1)単価も高く(2)人気度の高い「稼げるスキル」を可視化してみましょう。
これは二変量の変数なので、散布図で見てみます。
plt.scatter(x=likes, y=price) #軸に名前を付ける plt.xlabel("Likes") plt.ylabel("Price") #タイトルをつける plt.title("Scatter Plot on Likes and Price of Services")
で、でてきたものがこちらです。横軸にいいね数、縦軸に単価を設定しています。

それでは、もう少し条件を変えてみます。
- 単価が10000円以上で、
- いいね数が20以上のスキル
のスキルセットを見ていきましょう。
df = pd.read_csv("output.csv",index_col=0) df = df[df.price >= 10000] #価格が1万円以上 df = df[df.likes >= 20] #いいね数が20以上 df.head()
その結果がこちら

- 奇跡!現役ギタリストがあなたをギターの天才にします: 24いいね 10000円
- 楽曲制作☆オリジナル楽曲制作致します:37いいね 20000円
- 確率と統計を用いた競艇技術を御案内しています: 42いいね 10000円
- 電子書籍 出版 プロデュースをします: 54いいね 10000円
- ジャグラー1k以内に光る台教えます: 24いいね 10000円
ほうほう、こんなスキルが(1)単価も高く(2)人気度の高い「稼げるスキル」なんですね。なんか、あれですね、
博打も極めると商売になるんですね...
賭け事を教えますってマネタイズしやすいのかなぁ(うまくいかなかったときどうすんだろマジで。)
でもまあ、博打除いても、楽曲提供とか、現役ギタリストが教えるとか、本業であまり稼げない場合でも再度プロジェクトでこういうところを収益化していくのはいい感じな気がします。(ただ、時間的コストをかなり食いそうなので、費用対効果がよいとは言えないなぁ....)
分析していて気づいたのですが、費用対効果、つまりそこまで時間を投資しなくても収益化できる要素も変数に含んだほうがよかったような気がします。
もしかしたら、少し価格を下げてみたら、コスパのよい稼げるスキルも見つかるかもしれません。制限を少し緩めます。
- 単価が5000円以上で、
- いいね数が20以上のスキル
df = df[df.price >= 5000 ] #価格が1万円以上 df = df[df.likes >= 20] #いいね数が20以上 price = df.price likes = df.likes plt.scatter(x = price, y = likes) plt.xlabel("price") plt.ylabel('lieks') plt.title("price more than 5000 yen and likes more than 20 scatter plot")

ほむほむ、出品の値段は5000円か10000円で決まってるのかしら。とりあえず、5000円の出品物を見てみよう。
df = pd.read_csv("output.csv",index_col=0) df = df[df.price == 5000 ] #価格が1万円以上 df = df[df.likes >= 20] #いいね数が20以上 df
結果がこちら
- 毎月千円で宝くじ当選確率をあげる購入方法を教えます 93いいね、5000円
- ランキング1位現役スロプロが貴方に合わせて教えます 87いいね、5000円
- リアルなドラム打ち込みサービス制作します 21いいね、5000円
- あなたの原稿を電子書籍にします 20いいね、5000円
- パチンコホールの大当たりの仕組み教えますいいね 23いいね、5000円
- 簡単な8ビートから丁寧に教えます 21いいね 5000円
- 作曲を音楽理論から解りやすく丁寧にお教えします 23いいね 5000円
- ♪歌が確実に上手くなるノウハウお裾分け、24いいね 5000円
- 『もうダメだ』と思ったあなた、救いが本にありますよ♪ 21いいね 5000円
- あなたを”本”で救います! 25いいね 5000円
- 原稿はあるけどやり方が・・。電子書籍出版をお手伝い 39いいね、5000円
- オンラインカジノで勝てるロジックを提供します 28いいね、5000円
結論 (1)単価も高く(2)人気度の高い「稼げるスキル」とは?
ということで、分析した結果(1)単価も高く(2)人気度の高い「稼げるスキル」は
- 賭博スキルの提供(5000円~10000円)
- 楽曲提供(5000円~10000円)
- 演奏・音楽スキルの提供(5000円~10000円)
が単価が高いようでした。このようにマイニングしていくことによって、ある程度売れやすいスキルと、儲からないスキルを可視化することができました。売れるスキルがわかっていれば、出品する際の適正価格もわかりそうです。
ココナラのほかの出品サービス
さてさて、ココナラでは、
- プログラミングのメンターサービス
- Webスクレイピング代行サービス
- 就活相談サービス
など、いろいろなサービスをやっています。売る側としては、大学生が少し稼ぐぐらいのことや、副業としてやってみたり、情報商材を販売したりと、いろんな方法でマネタイズをすることができると思います。
逆に買う側としては、いろいろ探したけどなかったサービスなどがここで見つかることもあります。個人的にめっちゃありだなと思ったのは、プログラミングのメンターサービスでした(普通にプログラミングスクール通うと5万円くらいなのが、ここだと5000円くらいで学べるので。)学生さんで、プログラミング勉強している人だったらマジでおすすめです!
ということで、ココナラに興味があったら、ぜひ登録してみるとよいかと。

